In our last post, we introduced the Synthetic Data Vault (SDV) — a software system that allows users to input a dataset and generate synthetic data. The SDV was born out of academic research at MIT — but in 2018, we open-sourced it, so that people all over the world could use it.
Since then, we've been listening carefully to our community's feedback, making sure that we address any gaps between theoretical academic research and practical use. This multi-part series details recent improvements we've made so that SDV works in the real world. In this article, we focus on the machine learning-based modeling techniques that form the core of the system, while Part 2 will cover the surrounding workflow.
What's in a model?
At its core, the SDV is a set of machine learning models designed to understand and mimic real world data. Once the SDV creates a particular model, developers can generate synthetic data by sampling it. For synthetic data to be successful, this generative model must be correct — but through discussions with our open source community, we realized that there is no such thing as a single, winning approach that works every time. Each dataset and use case is different.
Our solution is to provide choices, giving users all the necessary tools to make useful synthetic data for each new case at hand. Let's dive into three popular uses of the SDV where such options are available: Tabular models, sequential data and business logic.
More Options for Tabular Models
The earliest version of SDV was based on a classic statistical method: Gaussian Copulas. This model is transparent by definition. It allows us to understand and exert control over formulas in the model, notably the distributions of each variable. This can be especially useful for business applications, where data often follows predictable distributions. For example, wind speed is known to follow a Weibull distribution, biological measures like height usually follow normal distributions and credit default rates often follow exponential distributions.
Meanwhile, advances in the AI space had also produced a robust, alternative model for those willing to sacrifice transparency: A deep learning technique called Generative Adversarial Networks (GANs). GANs model complex processes that don't follow known formulas. While these models’ inner workings aren’t easily explained by humans, they produce highly accurate results. We created a GAN, called CTGAN, specifically for synthetic data. This black box model is especially good at figuring out complex correlations between variables in large datasets.
For a long time, SDV allowed users a choice between our Gaussian Copulas based model, called GaussianCopula, and CTGAN to model tabular data. While this choice provided some flexibility, our users reported they had a hard time choosing between such extreme alternatives. We wondered if a middle ground was possible: Could we specify distributions while also using GANs to identify complex correlations?
We couldn't find any model that fit both of these requirements, so we made our own! A key insight was that we could use Gaussian Copulas to understand the data and transform it before applying it to a GAN. The result is CopulaGAN, a hybrid model we released in October 2020.
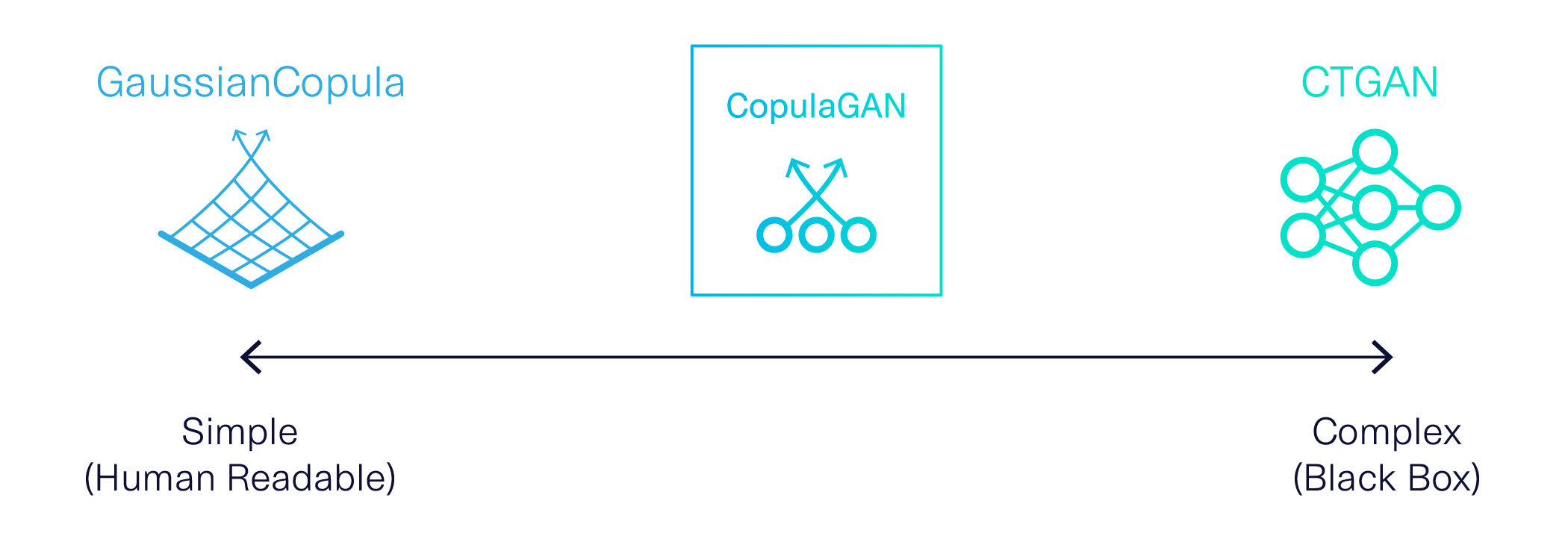
CopulaGAN combines the human accessibility of Gaussian Copulas with the robust accuracy of GANs. This innovation provides users with a new choice: a hybrid approach.
The Special Case of Sequential Data
Another tricky case pointed out by our users involved sequential data. While sequential data is stored in a table, it is unlike a regular table in that its rows are linked together, usually by a time component. This use case is extremely frequent, especially in finance — any table with credit card transactions, stock prices, or payments is almost certainly sequential.
At the time, solutions treated sequential data as a case of general tabular modeling. After all, sequential data is inside a table. However, these solutions failed to incorporate the key information that makes sequential data unique: The relationships that exist between rows.
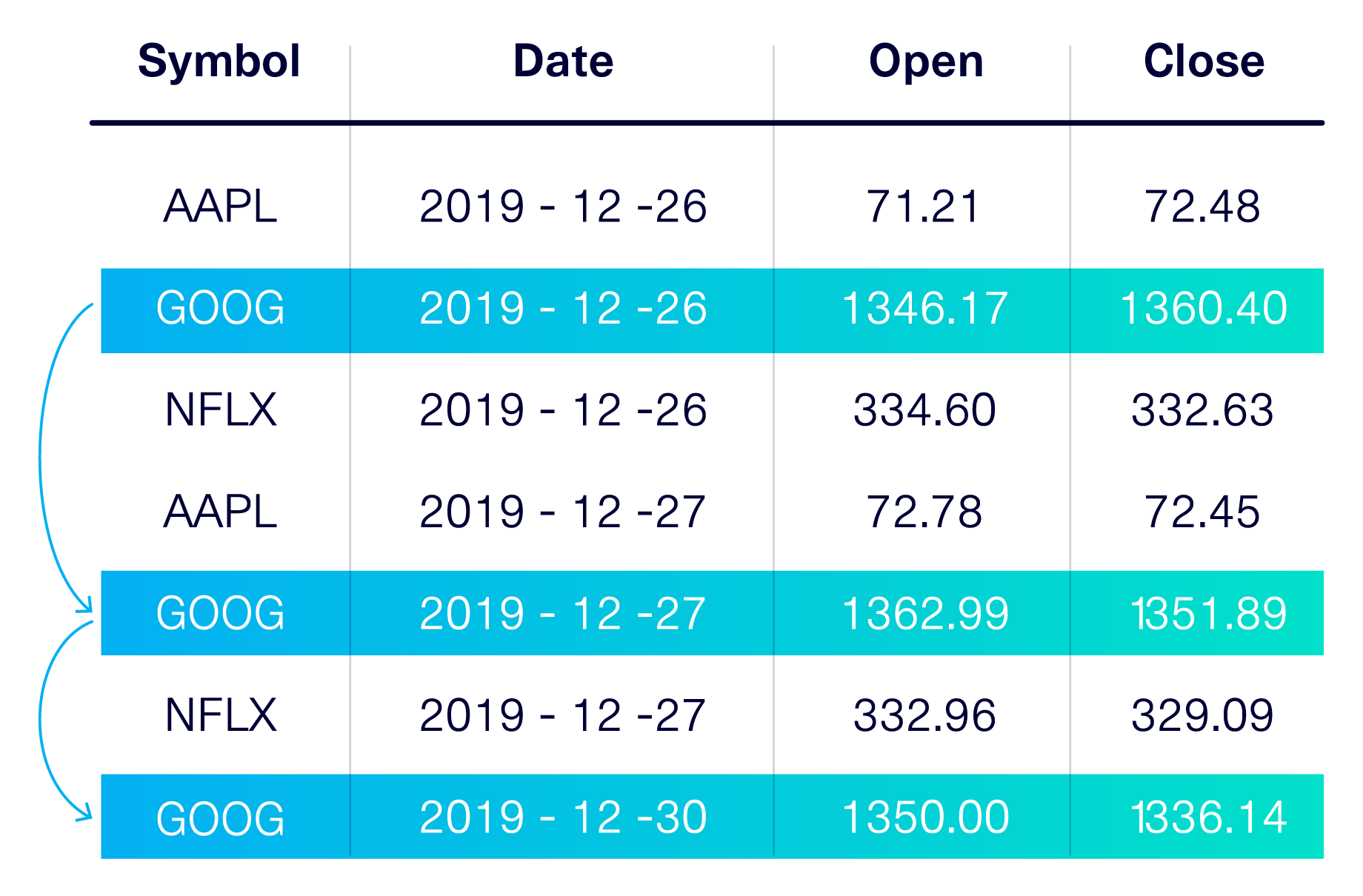
While considering this pain point, we recognized sequential data as an entirely new case that required its own unique set of modeling techniques. In October 2020, we released our DeepEcho library, which focuses entirely on sequential data. We also introduced our PAR model: a GAN approach made specifically for sequential data.
Encoding Business Logic using Constraints
Even with a plethora of modeling choices, it's vital to capture nuances in business logic while modeling synthetic data. This is due to differences in how humans and machines understand datasets.
Often, humans can easily glean the meaning of a dataset using context clues. Consider a table showing the names and ages of students and their legal guardians. A human will intuitively realize that a student must be younger than their guardian.

But will a machine understand the same rule? Because all of the SDV's models use statistics, they analyze trends generally — meaning that in this case, they will include a small possibility that a student could be older than their guardian. After all, is it totally out of the question that an older individual could enroll and list their child as their guardian? Either way, only a human expert can truly figure out what makes sense for this dataset!
To solve this pain point, SDV introduced the concept of constraints in July 2020. Constraints give users the ability to encode their business knowledge and expertise into an SDV model. In our example, they could specify that a guardian's age must be greater than the student's. Currently, the GreaterThan and UniqueCombination constraints allow for easy handling of common scenarios. We also provide a blanket CustomConstraint class, which gives users flexibility to capture more nuanced knowledge.
More Community Feedback
We believe that the more humans and machines can work together, the more efficient our processes can become. In this article, we explained how user feedback about the SDV led to new core modeling techniques and innovations — enabling a system that now provides a choice of multiple models, handles sequential data, and understands constraints. In Part 2, we will discuss similar feedback-driven innovations in the rest of the workflow.
Using SDV — and giving us feedback — fuels this rapid evolution. To start a discussion, please message us on Slack or file an issue on GitHub. Working together, we can make SDV the most trusted, transparent and comprehensive platform for synthetic data generation!
For other inquiries, please contact info@sdv.dev.


