
Hello world! We, the creators of MIT's Synthetic Data Vault, warmly welcome you to our official blog. Soon we'll be using this space to deep-dive into topics related to our libraries, and to unpack ideas in the synthetic data space. We're looking forward to exploring this exciting area with you.
But first, we want to properly introduce our project: The Synthetic Data Vault (SDV), an open source software ecosystem for generating synthetic data. In this post, we’ll explain why synthetic data is important, and tell the story of how we created the vault. We’ll also lay out what’s in store — and how you can get involved. Let’s get started with a brief overview.
Synthetic Data What?
Synthetic data is a bold new frontier in machine learning. It allows developers to share and use data more effectively.
It may seem counterintuitive, but although billions of gigabytes of data are produced every day, there are still huge gaps in what developers are actually able to use. Accessibility concerns, regulatory issues and imbalanced datasets can all keep experts from using data. This impedes progress in finance, health care and other domains.
Good synthetic data can fill these gaps. The SDV uses machine learning to analyze data. Then, it creates fully synthetic datasets that mimic the original. Although the synthetic data is entirely machine generated, it maintains the original format and mathematical properties. This makes synthetic data versatile. It can completely replace the existing data in a workflow, or it can supplement the data to enhance its utility. Already, our users have successfully used the SDV to augment datasets, test applications, remove bias and more.
A History of the SDV
Our story starts in 2013. In MIT's Laboratory for Information and Decision Systems (LIDS), we were working on general data science projects. We had developed new techniques, and we were excited to test them on real datasets. However, as soon as we asked for the data, we hit roadblocks. The process for getting access to data turned out to be much more complex than we anticipated, with many regulations and security red tape.
We wondered: What if we didn't need the real data in the first place? If we had synthetic data with the same mathematical properties as the original, it would be much easier for everyone to share and use.
In 2016, we released a paper describing the very first iteration of the SDV. It introduced a novel technique for synthesizing multi-table data, and included trials where data scientists successfully used synthetic data instead of real data for machine learning tasks. Related research to come out of the lab included CTGAN, a novel approach to generating synthetic data using deep learning.
After these successes in the research community, we decided to move beyond purely academic solutions. Synthetic data has the potential to solve real-world problems faced by people on all sides of data science: internal developers writing software, external contractors working offshore, 3rd party partners offering services and even the end users who create the data. After some pilot testing on enterprise applications, we open sourced our work in 2018, publishing sdv on PyPi for general use. Open sourcing offered ample opportunities for collaboration and customization. It allowed users all over the world to test the SDV in enterprise settings, and helped the SDV ecosystem evolve into a one-stop shop for synthetic data needs!
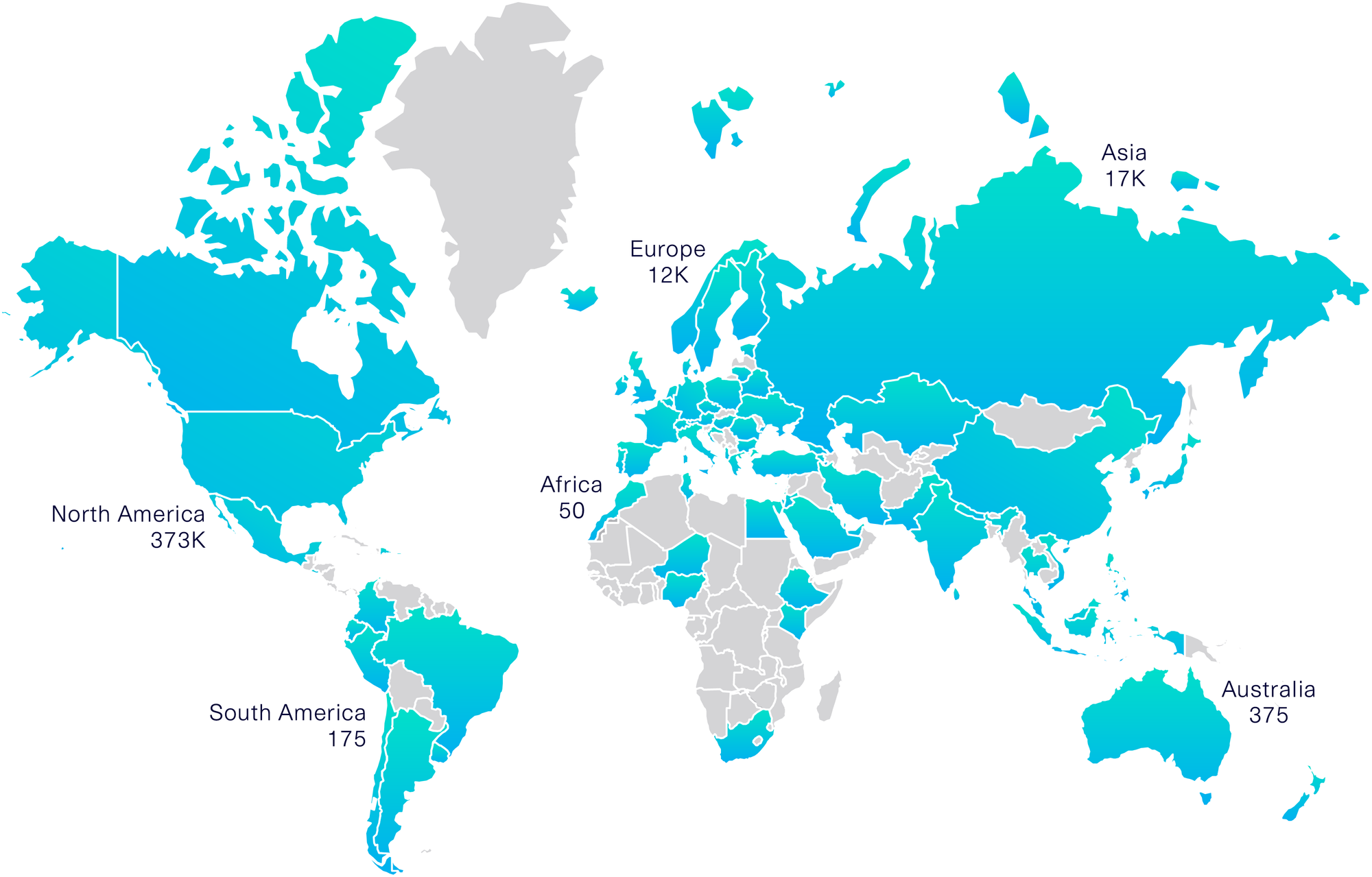
We listened to feedback and, as of today, have made 93 releases (across all our libraries), addressing 504 issues. We have been thrilled to see a burgeoning community of invested users using the SDV to solve problems. We've seen over 200K user downloads from PyPi, 400 stars in the SDV GitHub repository and 200 developers in our Slack channel. Our community is global and includes people in diverse roles: academics, data scientists, operations managers, engineers and more. We are continually learning from our community, and we're excited to bring new innovations to you!
Just the Beginning
Synthetic data has the potential to revolutionize the entire field of data science, allowing us to solve problems that once seemed untouchable. We want the Synthetic Data Vault to be the most trusted, transparent and comprehensive platform for synthetic data generation, but we can't do it without our users. It's our ever-growing open source community that allows us to quickly repair bugs, triage feature requests and improve to serve a variety of real-world needs.
That’s where you come in. If you’re already a member of this community, we can’t thank you enough. And if you’d like to get involved, see below for ways to get started. Either way, watch this space for more nuanced discussions about synthetic data. We're excited to share what we've learned from you, and show how we are collectively improving the ecosystem. It’s time to open the vault!
Want more ways to get involved?
- Follow us on Twitter @sdv_dev for release announcements, blog updates and more
- Join our Slack community to meet other users, discuss synthetic data solutions and suggest topics for the blog
- Visit & star our GitHub repositories
- If you've successfully used the SDV for your project, share your experience and tag us
For other inquiries, please contact us at info@sdv.dev.
*Total download statistics per continent come from the Linehaul project using BigQuery, and include mirrors. Are you aware of more accurate ways to count Python package downloads? Let us know!


