Data is a great source of information. Real data — which is based on observations of real-world phenomena like weather, movements on a factory floor or the activities of a user base — can help us notice trends, increase business efficiency and solve problems.
But data can be helpful even if it isn’t real. This data, sometimes called fake or test data, doesn’t come directly from real-world observations, but is instead artificially crafted by a human or machine. The latest and most complex iteration of this data type — what we call synthetic data — builds on previous work done in this space.
In this article, we'll go through the history of fake data. By the end, you'll be able to answer the following questions:
- What were the original motivations and tools for manually creating data?
- What differentiates synthetic data from other types of fake data?
- What role does machine learning play in generating synthetic data?
The Dawn of Fake Data: Test Data Management
One group of people has worked with fake data for a long time: software engineers. They need data in order to test the systems they build, and the real stuff isn't always usable (for example, due to privacy).
Let's pretend it's the early 2000s, and you're an IT professional working at a bank. You're responsible for the software that updates account balances after each transaction. You'd like to test this software before putting it into production. What do you do?
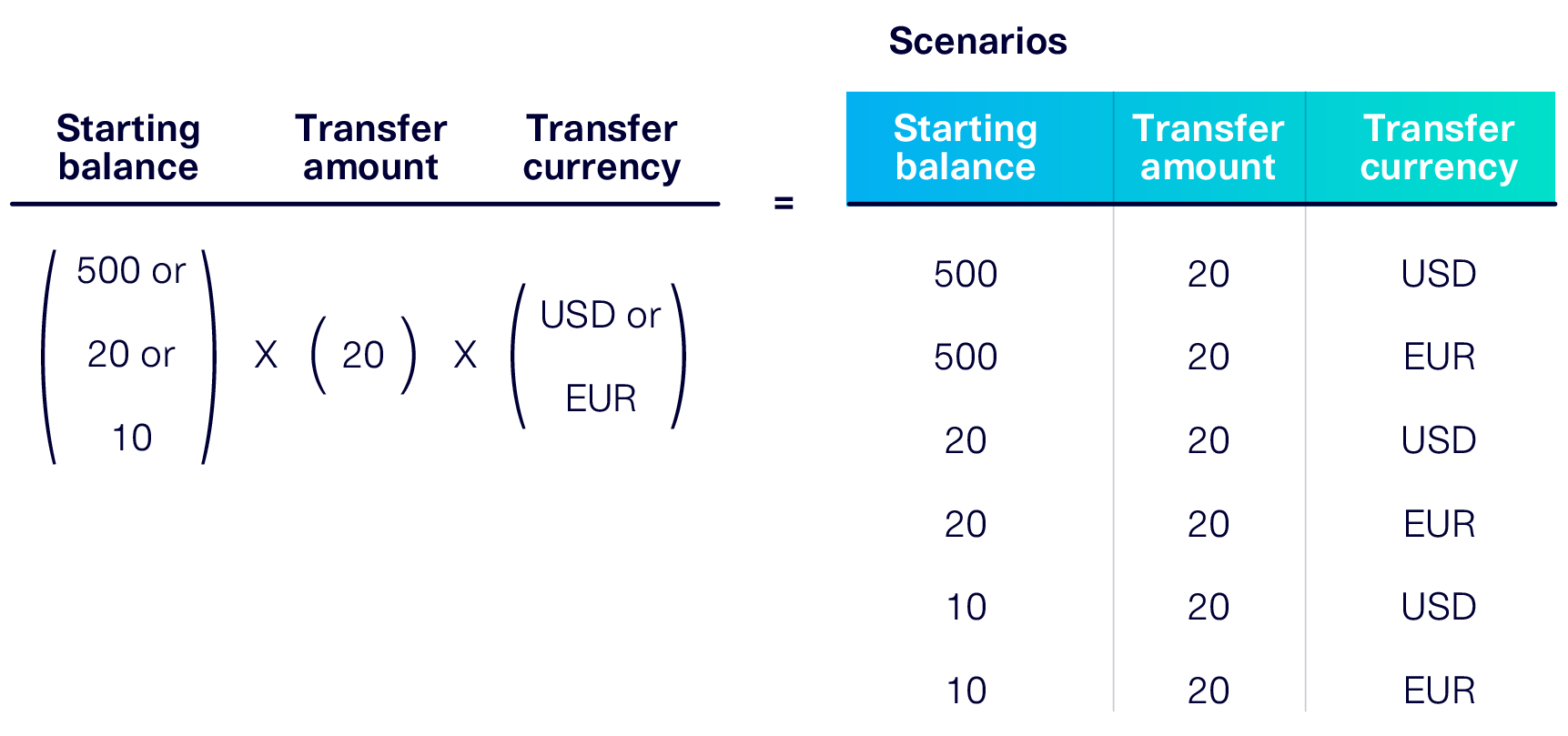
Most likely, you'll come up with a few test scenarios to ensure that your functionality — updating the balance — can properly handle a variety of inputs.

Notice that in order to create these scenarios, you had to generate data: various starting balances ($500, $20, $10) as well as a transfer amount ($20). This is an early version of using fake data in order to test your software!
Using Tools for Manual Creation
Now let's fast forward in time. Over the years, your software has gotten even more complex, and you're constantly adding new functionalities. For example, maybe you start allowing transfers with foreign currency.
You need to test these functionalities before you roll them out. To save time, you might end up using -- or creating -- a tool that allows you to generate and manage fake data for testing.
The simplest tool may be a basic permutation, as illustrated below.
A more sophisticated tool might allow you greater control over the rules the data must follow. It will also allow you to create more columns as your functionalities increase. For example, maybe the bank now offers two different account types: Premium and Normal.
Now you need a test data generation tool that can handle all of these variables and come out with something like this:
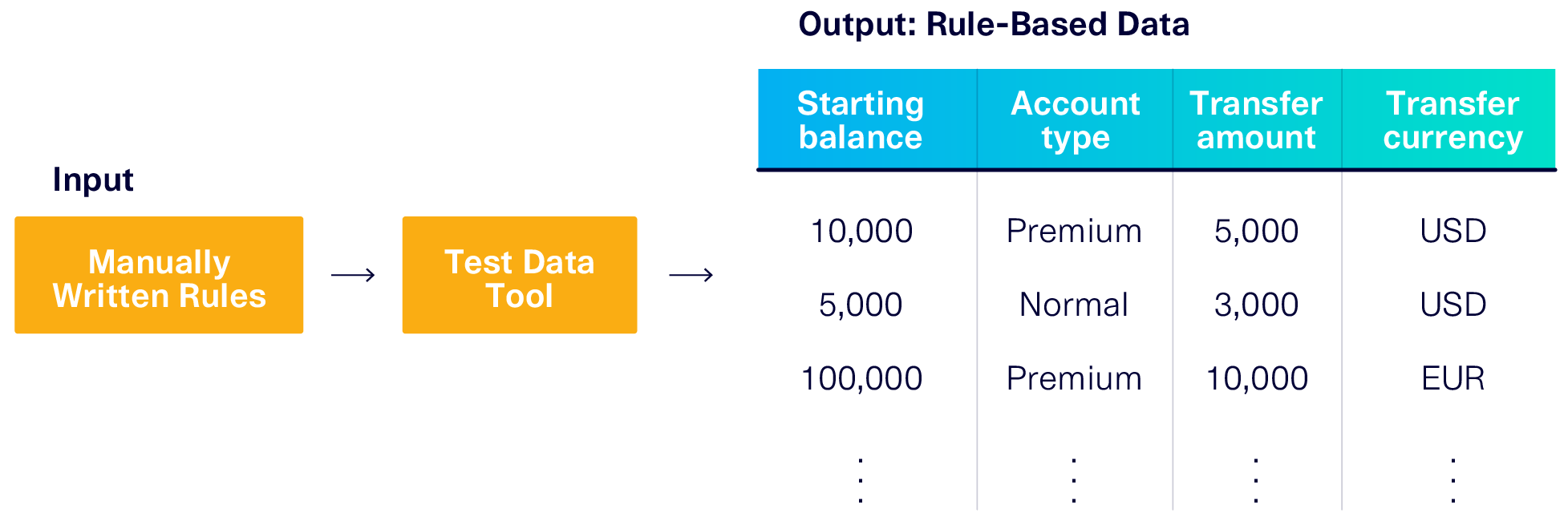
Many test data management tools use sophisticated logic to precisely create these data columns and their values. But the rules they use are manually written, and rely on human intuition and domain knowledge. For example:
- Account type = Premium 10% of the time and Normal 90% of the time
- Starting balance is between $10,000 and $250,000 if Account type = Premium
or between -$1,000 and $10,000 if Account type = Normal - Transfer amount follows a bell curve with a mean of $7,500 and standard deviation of $1,000
- Etc.
There are downsides to this manual approach. It takes time and effort to come up with these rules, to keep track of them, and to update them as your application changes.
Adding Machine Learning
Adopting machine learning (ML) opens up entirely new avenues in data generation. In the process, it gets rid of some of these downsides.
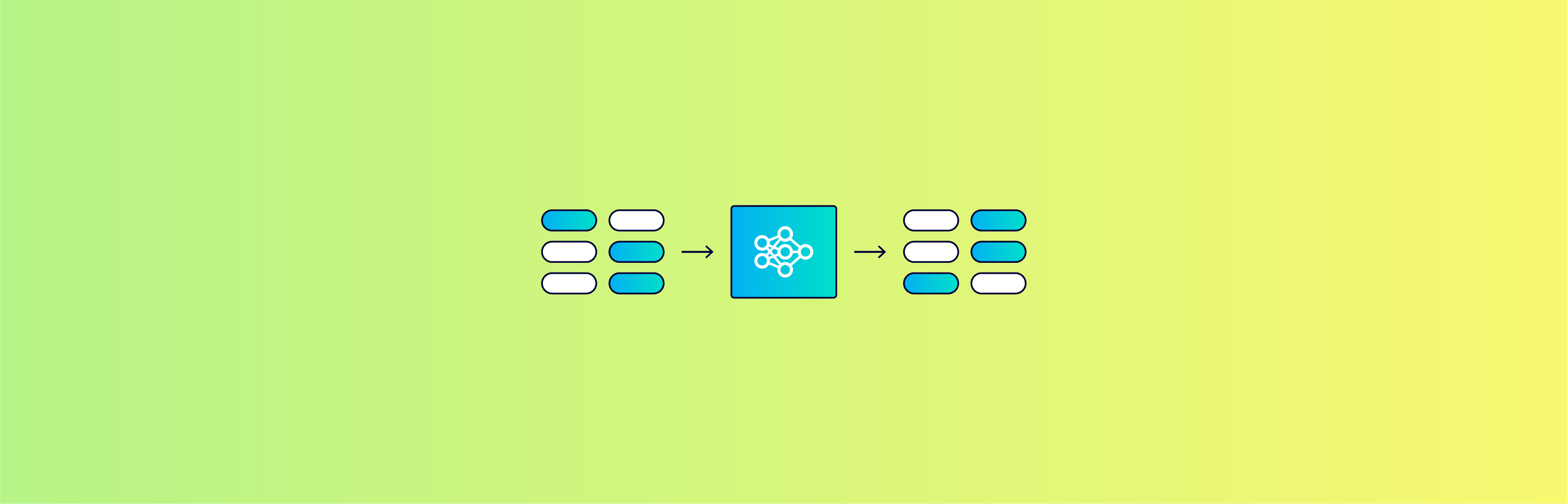
At a high level, ML-based software (such as the Synthetic Data Vault) works in three steps:
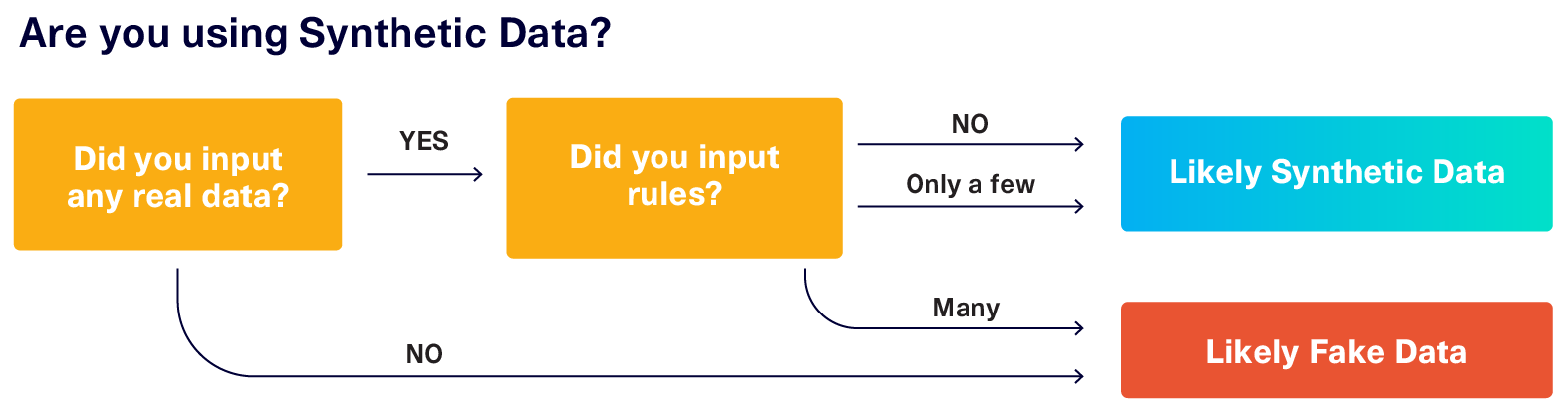
- The user inputs real data into the ML software
- The ML software automatically learns patterns in the data
- The software outputs data that contains those patterns
Let's go back to our banking example to see how this works. It's now 2021 and you're using the SDV to generate your test data. You input all the transactions your bank has handled in the last week.
After modeling, the SDV outputs entirely new data that looks and behaves like the original. An illustration of this is shown below.
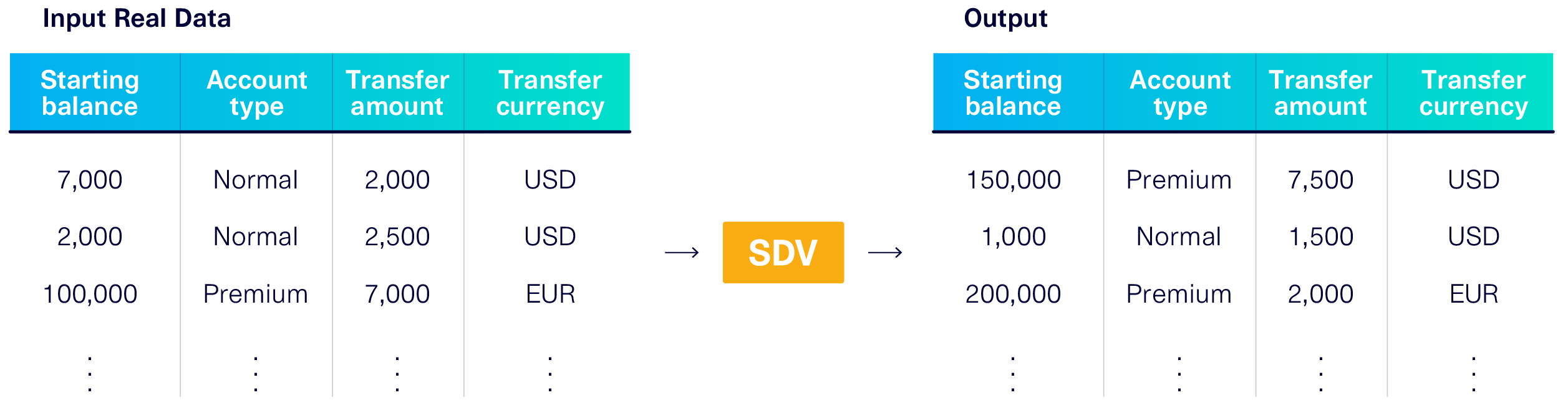
Notice that the output data contains many of the same properties as the original. The model learned all of the following information:
- Ranges & Categories. Transfers range from $5K to $10K. Bank accounts can be either premium or normal. Etc.
- Shapes. 10% of accounts are premium. Transfers follow a bell curve distribution with a mean of $7,500 and a standard deviation of $1,000. Etc.
- Correlations. Premium bank accounts tend to have higher balances ($10K to $250K) than normal accounts (-$1K to $10K).
In other words: while the old test data management tools required you to manually come up with rules, ML-based tools learn these rules automatically. Moreover, they can learn new information. For example, the ML picked upon a couple of extra correlations:
- Premium accounts are more likely to transfer foreign currency.
- Normal accounts are more likely to be overdrawn (transfer more than their current balance).
Using an ML-based data generation tool will help you ensure that your software is robust against these typical cases. And while manual data generation tools generate fake data, ML-based approaches generate what we call synthetic data.
Benefits of Synthetic Data
There are some clear advantages to using synthetic data over fake data, especially in software testing. Below, we've detailed a few.
- Saves time with automation. Because ML automatically learns patterns from the real data, there is no need to spend a lot of time coming up with and inputting rules. ML learns rules that you may even miss.
- Is usable by non-experts. Realistic fake data can only be generated by domain experts, who know the precise rules governing the dataset. However, anyone can generate synthetic data. All they have to do is input the real data and the ML software takes care of the rest!
- Increases adaptability. Applications and data will inevitably change over time. It's easy to update synthetic data as this happens, simply by retraining the ML model with newer data.
Benefits of synthetic data expand beyond software testing. The SDV Community is using synthetic data for an ever-increasing variety of tasks, including machine learning development, de-biasing datasets and scenario planning.
Key Takeaways
In this article, we surveyed numerous ways of creating and using data that is not real. In particular, we learned that:
- Creating fake data is not a novel concept. Older generations of tools will output fake data when given an explicit list of rules. This is especially useful for software testing.
- Adding ML to this process is a newer evolution. Users input real data into the ML model, and it's able to automatically infer the rules. Data generated using ML-based systems is known as synthetic data.
- Synthetic data's key advantages include its automation and adaptability. The uses of synthetic data expand beyond software testing.
In future articles, we'll put ML models to the test! We'll uncover their strengths and weaknesses, and guide you through getting the most from synthetic data using the Synthetic Data Vault.


